
NeuroAI image alignment, brain scaling laws, & brain-to-text decoding
Digest of my takes on neuro and/or AI research papers

Reading a paper’s abstract or an AI-generated summary often lacks a lot of nuance, and relying on Twitter or science news sites often yields overly hyped impressions. Below are my personal takes on a few papers that caught my interest in the last month1. Text in code blocks represent my raw, unedited notes written while I read the papers.
one-sentence paper takeaways
1. Human-Aligned Image Models Improve Visual Decoding from the Brain
https://arxiv.org/pdf/2502.03081v1

The authors show that if you map brain activity collected while viewing images to the latent space of a frozen image encoder, this alignment is better if the image encoder was first fine-tuned on behavioral human similarity judgments. Very interesting goal and well-written paper, however, I don’t know if I agree with their conclusion that this represents a new perspective on learning brain-to-image mappings… E.g., they compare performance retrieving a seen image from brain activity via alignment to CLIP image latents versus alignment to latents from “human-aligned CLIP”—the same model fine-tuned using Dreamsim metric (which is based on human behavior judging similarities of images). But isn’t the human-aligned CLIP model an inherently better model when it comes to general (non-brain) retrieval tasks? That’s what the conclusion for Sundaram et al. (2024) showed. Given this, wouldn’t you expect the image encoding model that does better on retrieval tasks to provide the better latent space for brain-to-image retrieval?
My bigger takeaway from this paper is that I need to dive more into SynCLR. The authors tried out lots of different image encoders (e.g., CLIP, OpenCLIP, DINOv2, SynCLR) and SynCLR seemed to do the best, particularly their human-aligned SynCLR. And SynCLR is a really interesting approach to training an image encoder—you use exclusively synthetically generated images and captions and do contrastive learning where images with the same caption reflect positive pairs. And it made me think a bunch of research follow-ups to SynCLR (see notes).
Another idea I had is whether DreamSim could be further improved if fine-tuning involved both behavioral similarity judgments alongside literal brain activity corresponding to looking at the images (which could be approximately obtained from existing datasets).
Image retrieval from brain activity during image viewing improves by up to 21% by using human-aligned image encoders (used THINGS-EEG2 and THINGS-MEG)
They find that human similarity judgment datasets capture early human impressions of images more closely aligned with brain signals
They train a brain encoder such that embeddings are aligned to the outputs of frozen image encoders, using InfoNCE loss
The frozen image encoders they try are ViT, CLIP, OpenCLIP, DINO, DINOv2, SynCLR, concatenated DINO+CLIP+OpenCLIP. They fine-tune each of these using Dreamsim metric and these become the respective human-aligned models (aka Dreamsim-finetuned models) for comparison.
Fu et al. (2023) introduced Dreamsim, a metric fine-tuning vision models on a human image similarity dataset.
Sundaram et al. (2024) found that human-aligned models, aka fine-tuning existing models on human similarity judgments, do better on retrieval or semantic segmentation downstream tasks but worse on other downstream tasks like counting. NIGHTS was best similarity judgment dataset to use in contrast to BAPPS or THINGS.
As such, it's actually expected that image retrieval from brain activity does better for the DreamSim models right? They are already better at retrieval tasks than their non-human-aligned counterparts.
SynCLR's human-aligned model did the best by a reasonable amount across all the models tried. So maybe our MindEye style image retrieval should instead use human-aligned SynCLR embeddings instead of CLIP
**SynCLR** is an approach that uses exclusively synthetic images and captions, without any real data via an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption; then do contrastive learning where images with same caption reflect positive pairs. SynCLR does particularly well on semantic segmentation and is otherwise competitive with other models like CLIP and DINOv2. In contrast, consider that SimCLR treats every unique image as a different class and so are pushed apart regardless of how different the semantics are. On other hand, supervised methods like SupCE will use very broad classes like “golden retriever” as positive pairs and ignore nuances of whether two photos are golden retriever on a bike vs. another two images are golden retriever in a dog house—these can reflect outputs from two different captions using SynCLR and hence become two classes as opposed to 4 (with SimCLR) or 1 (with SupCE).
**SynCLR would be a great journal club article**
Follow-ups im interested in:
1. Use more diverse captioning and use several (instead of one) text-to-image models to derive the synthetic image generations
2. Improve upon DreamSim approach to not have the downfalls with respect to some downstream like object counting
3. Use both NIGHTS and NSD brain activity to fine-tune a la DreamSim, so both perceptual judgments and brain latents
4. Use SigLIP loss instead of InfoNCE CLIP loss
5. See training recipe from **clip-rocket** https://arxiv.org/pdf/2305.08675 that uses weak and strong augmentations and weak and strong projectors; original CLIP training just used weak augmentation of random crop and didnt use any text augmentations
1. Their finding is that a simple CLIP baseline can be substantially improved by applying this improved training recipe, composed of image and text augmentations, label smoothing, dropout, and deeper projector networks. If you do that, CLIP beats SSL and “improvements” to CLIP like BarLIP SiamLIP BYOLIP SwALIP
2. label smoothing = soften the identity matrix otherwise used as target in contrastive loss
3. code available: https://github.com/facebookresearch/clip-rocket2. Scaling laws for decoding images from brain activity
https://arxiv.org/pdf/2501.15322
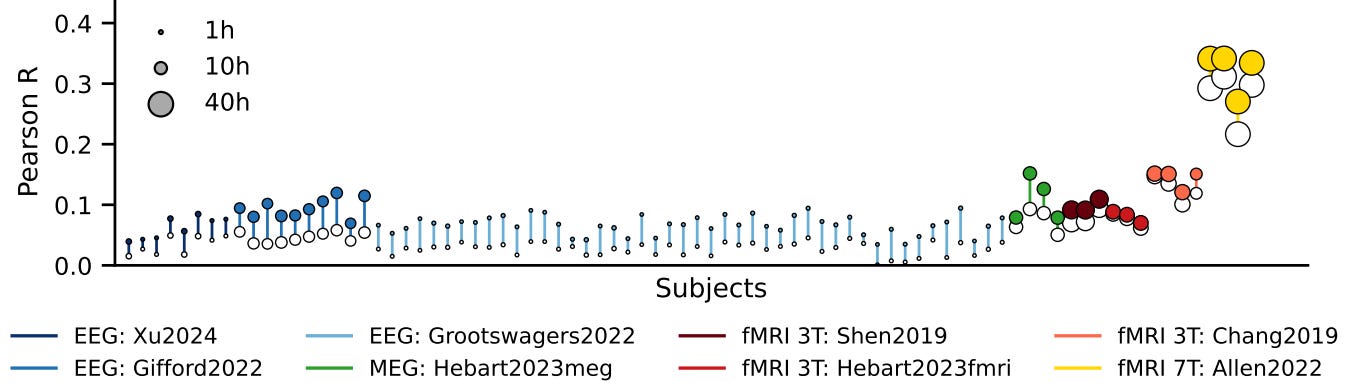
This paper computes and compares scaling laws across various non-invasive brain modalities corresponding to neural activity collected while humans looked at images. One big takeaway is that they observed no plateau of decoding performance increasing with additional training data, following log-linear scaling law. They also observed much more gain from using big data collected across a few densely sampled subjects (as opposed to big data from lots of subjects each of whom had relatively little data).
Which brain modality is best to invest into to take advantage of scaling brain data? They claim it’s MEG but I think that might partly be because that aligns with their past research objectives rather than the actual results of this paper? They show in their results that the best scaling potential after accounting for factors like number of trials/time to collect/cost to collect is fMRI 7-tesla, followed by MEG, followed by fMRI 3-tesla, followed by EEG. The fact that fMRI 3-tesla does not show as much promise as MEG could potentially be explained by the dataset used in the studies they pulled from (e.g., using THINGS instead of COCO) and due to those studies perhaps using a suboptimal MRI protocol (we’ve been experimenting a lot recently with how protocol can affect MindEye performance using 3-tesla MRI at Princeton).
Also of note is that the authors accomplished a great feat here with developing a unified pipeline and benchmark across all these separate neuroimaging datasets and modalities. It’s unfortunate that their code that accomplishes this is not released.
Compared scaling for single-trial image decoding using EEG / MEG / 3T fMRI / 7T fMRI
Largest benchmark to date encompassing total of 8 public datasets and 2.3 million brain responses to images, or 498 hours of brain recording
Conclusion is that decoding is obviously best with better modalities, but the importance of deep learning compared to linear is most pronounced for worst modalities. **Also no observed plateau of decoding with increased training data. It follows log-linear scaling law. Little gain from more subjects, big gain from more same-subject data.**
Although they dont appear to show *any* gain in multi-subject modeling, which goes against our MindEye2 results.
Their measure of performance is correlation between ground truth and predicted DINOv2-giant image embeddings (the "average output token", 1 x 1536 dim). They also report the standard benchmark metrics used across other papers in the Appendix.
They didn't release their code that accomplishes a unified pipeline and benchmark across datasets?
They didnt use GLM for fMRIprepped data, they do do cosine-drift linear model for detrending at voxelwise level and subtract it from raw signal. Then z-score. They use 5 TRs per image relative from 3rd to 11th TR. They intentionally avoided fancy denoising for simplicity's sake given use of so many datasets, they arent trying to get sota performance here.
They say they adapted the conv architecture of MindEye1 for deep learning module, but we didn't use a convolutional architecture... it's an MLP.
They claim their combined retrieval and reconstruction loss comes from Benchetrit et al. (2024) but I think that originally comes from our MindEye1
Beautiful plots and clear mathematical notation.
They say that across all metrics (num trials, time, cost) 7T scales the best. 3T is not in second place, it's roughly tied with MEG regarding number of trials while EEG lags behind. In terms of total time, 3T/MEG/EEG are similar. Considering potential of scaling, MEG has largest slope after 7T fMRI.
They end with seemingly contradictory conclusion that 7T might not be most effective path to scaling because it's high cost and slow temporal resolution. This contrasts with their result that the potential of scaling shown as slope taking into account trials/time/cost is best for 7T, followed by MEG.
I think the 3T could be greatly improved with improved protocol, as we have first-hand evidence of. Also this difference in 7T to 3T could be explained by dataset, as latter used THINGS instead of COCO.3. Brain-to-Text Decoding: A non-invasive approach to typing
https://arxiv.org/abs/2502.17480

Another King lab paper, showing performance decoding sentences from EEG and MEG while participants typed memorized sentences on a keyboard. Note that brain-to-text decoding is already being done with neural implants, with already achieve fantastic character decoding (around 94%, Metzger et al., 2022; Willett et al., 2021). Obviously it would be great to be able to decode text from non-invasive modalities like MEG and EEG, but as seen by the results here they are good but not really good enough to really be practically useful. And remember that these results are not decoding internal thought but rather from motor cortex from the fingers typing sentences. For reference, they do sanity check “hand prediction” decoding (predicting which hand was typing 40ms after motor input, left or right) where their best model with MEG gets only 90% accuracy (EEG gets around 67% accuracy). Note that this should be really easy to decode, because it’s a physical hand movement that is being decoded and left vs. right motor cortex activity should be one of the easiest things to decode from the brain. Now on to their actual results, for their best subject, individual character decoding achieved 81% accuracy for MEG and 55% accuracy for EEG, which is very good all things considered!
Presents Brain2Qwerty for decoding sentences from EEG or MEG while participants typed briefly memorized sentences on QWERTY keyboard.
Part of their pipeline is to use pretrained LLM to correct predictions at sentence level. So for MEG they show example of the raw prediction being "ek benefucui syoera kis ruesgis" and then this automatically becoming "el beneficio supera los riesgos" due to the language model (which is a perfect prediction).
Sanity check: hands prediction (left vs right motor input; 40ms after motor input)
Linear decoding: 74% (MEG) and 64% (EEG)
EEGNet: 83% (MEG) and 70% (EEG)
Conv+Transformer: 91% (MEG) and 70% (EEG)
Brain2QWERTY: 90% (MEG) and 67% (EEG)
Individual character decoding:
Linear decoding: 27% for (MEG) and 22% (EEG)
EEGNet: 28% (MEG) and 22% (EEG)
Conv+Transformer: 62% (MEG) and 20% (EEG)
Brain2QWERTY: 68% (MEG) and 33% (EEG)
(best MEG subject 81%, worst 55%)
Basically, MEG decoding is quite good. EEG is quite bad.
But compare to implants, which attain character decoding of 94% (Metzger et al., 2022; Willett et al., 2021)
Compared to past work from same lab, MEG via listening perception they didn't attempt character-level decoding, instead doing 3-second "segment" decoding (from a pool of 1000 segments). Difficult to compare, but almost definitely worse decoding than reported here using motor movement.4. From Thought to Action: How a Hierarchy of Neural Dynamics Supports Language Production
https://arxiv.org/abs/2502.07429

And finally a third King lab paper from Meta—this is another paper related to people typing while getting their brain scanned. It’s moreso a neural mechanisms paper rather than a practical decoding paper. Using MEG and EEG, they examine the time-courses of decoding different representations, namely context/word/syllable/letter representations. They find different decoding time-courses for these different representations and conclude a hierarchical mechanism for language production, but I don’t really buy it… Can see my notes below for why.
Skilled typists typed on keyboard while scanned via MEG or EEG.
More a neural mechanism paper than application-based decoding paper.
Main result is that before the typist physically types the word, the brain generates "context" representation, followed by "word", followed by "syllable", followed by "letter" representations which are each separately decodable (albeit overlapping) from the brain.
Note that "context" here refers to decoding GPT-2 word embedding, "word" refers to Spacy word embedding, "syllable" refers to FastText embedding, and "letter" is one-hot-encoder.
Authors then conclude that language production follows a hierarchical mechanism that decomposes sentences into progressively smaller units that ultimately result in our motor movement of typing.
Cool to see the approach of comparing timecourses of decoding for different levels of representation. Interpretation-wise, though, my opinion is just because decoding for the different levels of representation weren't identical in terms of when they were best linearly decodable doesn't necessary mean that the underlying mechanisms are independent. Also, isn't it expected that "context" would be more broadly decodable across time than "letter"?
Also somewhat difficult to tease apart whether they are decoding "reading", like perception of the word, versus decoding premotor activity (preparing to type).Have you come across an interesting neuro or AI paper? Share with me at scottibrain+neuneuro[at]gmail.com.
A paper catching my interest doesn’t mean I am vouching that these papers are good! These are simply my personal takeaways and notes, so can be prone to bias or misunderstandings—please send me an email to correct me if you think I made a mistake in my interpretations of any paper!